Data Modeling
The first step in using TDengine IDMP to manage data is to build an asset model for your data. When your data is stored in a database consisting of two-dimensional tables, the relationships between these tables are not always perceivable. The purpose of data modeling is to help you define and visualize the relationships among these tables, making it easier to manage, locate, and analyze your data.
Data Catalog
TDengine IDMP uses a tree hierarchy to manage data assets and build a data catalog. Each node in this tree corresponds to an element. With this tree-structured data catalog, you can easily browse your data assets.
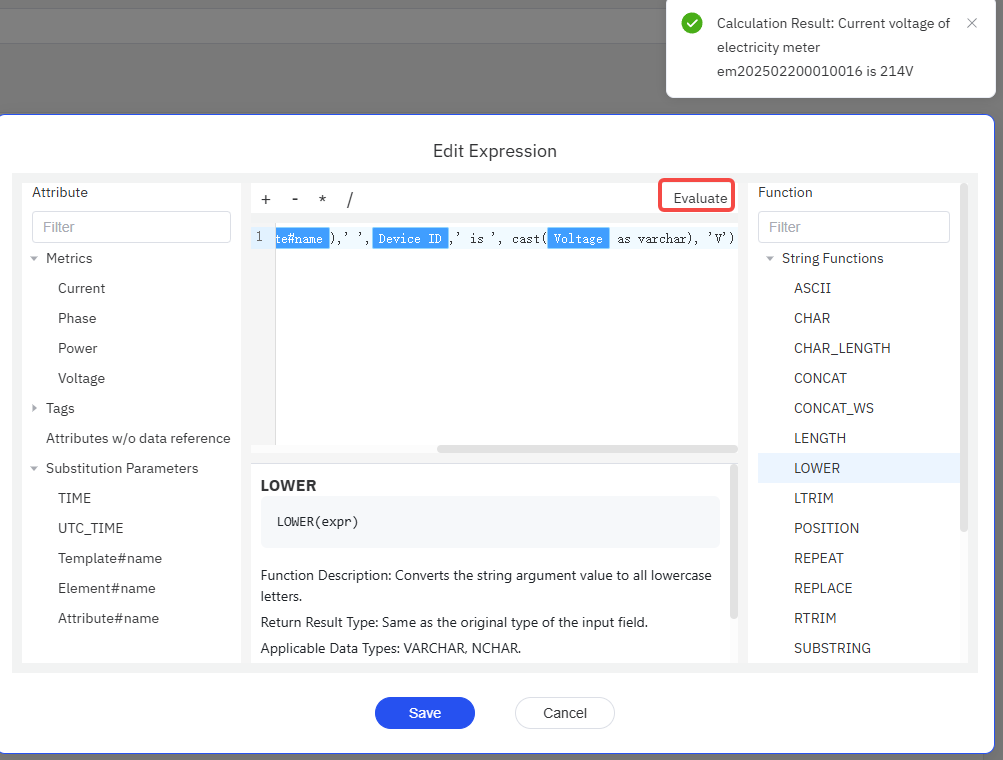
The modeling process involves continuously creating elements and building out the data catalog into a structure that reflects your real-world scenario. Imagine you work at a power company that operates multiple wind farms, each of which contains wind turbines and inverters. You could take a top-down modeling approach, starting by creating an element called All Wind Farms, and under that, creating elements for each wind farm, such as Wind Farm A, Wind Farm B, and so on. Under each wind farm, you could then add multiple wind turbines and inverters. In this way, the data model is built level by level, as illustrated in the following figure:
If the organizational structure is not yet clear, you could also use a bottom-up approach. For instance, you might start by creating a wind turbine element, configure it fully, and ensure it is operating correctly. Then, you could create a wind farm element and move the turbine element under the wind farm.
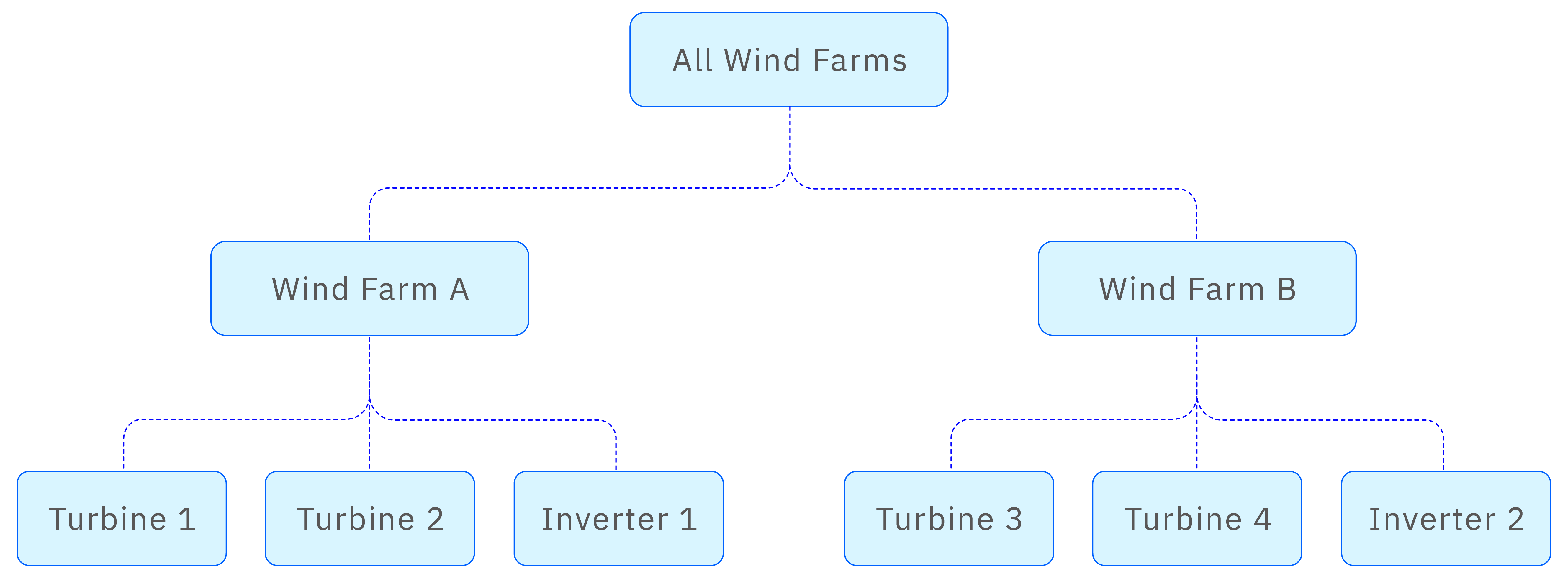
Enterprise asset management often involves multiple organizational models, and different roles may require different data perspectives. For example, operations personnel may prefer to organize the tree structure by site or plant, as shown above, while equipment maintenance teams may prefer to organize it by equipment type, like the following figure:
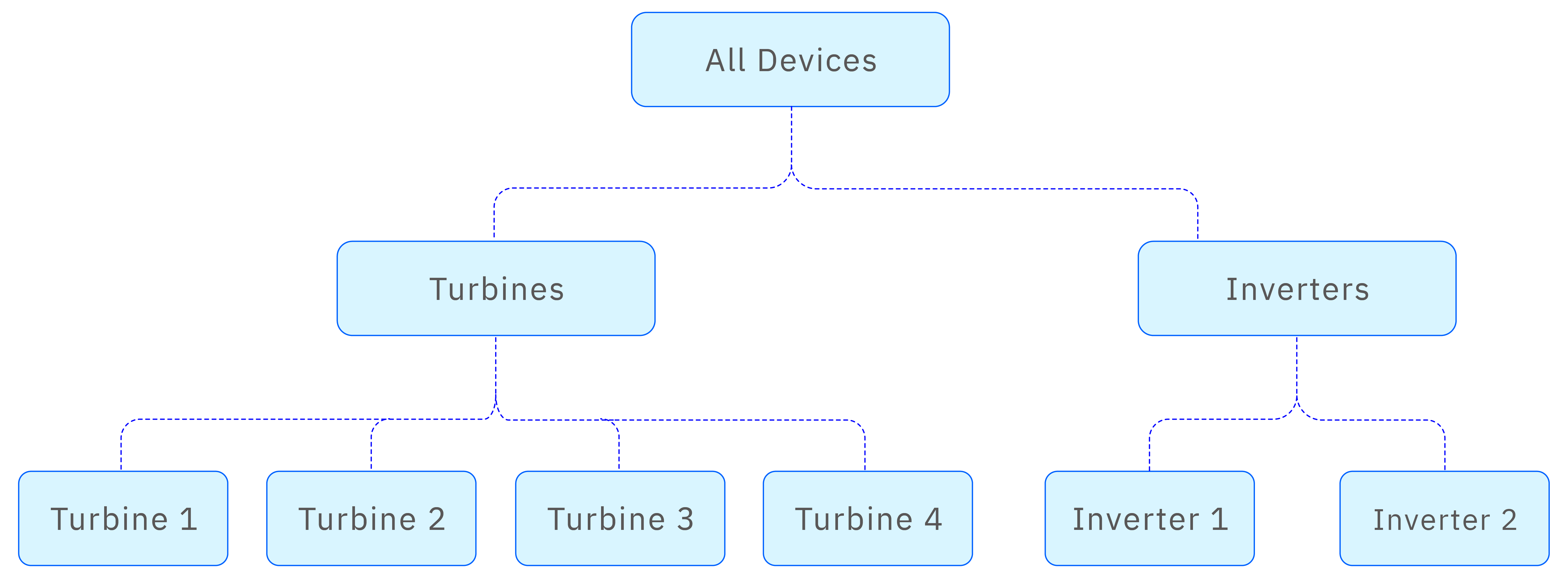
In TDengine IDMP, an element can belong to multiple hierarchies through element referencing, making it easier to manage from different perspectives. In the case of wind power, you could construct a tree containing both perspectives:
 Although elements such as turbines are repeated in the tree, element references are used to reduce duplicate data and ensure consistency. For more information, see Element References.
Although elements such as turbines are repeated in the tree, element references are used to reduce duplicate data and ensure consistency. For more information, see Element References.
Creating Elements
To create a child element, hover over an existing element in the sidebar and click the three-dot menu on the right. From the drop-down menu, choose New Child Element.
You can choose whether to use an element template and specify the reference type. If you are not sure, retain the default strong reference type. After clicking Confirm, you can configure the name, category, location, and description of the element.
If you need to create multiple elements that represent the same type of device, create an element template first. This allows for batch creation and management of elements while ensuring data standardization. To create an element template, click Libraries in the main menu, select Element Template in the sidebar, and then click the New Element Template (+) icon in the action bar.
You can also copy existing elements and paste them to create similar elements quickly.
After you create an element, you can modify or delete it. In the sidebar, you can also drag and drop an element to another node, which creates an element reference. These operations are designed to help you flexibly build and adjust the tree structure.
Defining Attributes
An element can have many static and dynamic attributes. Creating your tree hierarchy and configuring appropriate attributes lets you map the physical world to the digital world and form a digital twin.
To define an attribute, hover over an existing element in the sidebar and click the three-dot menu on the right. From the drop-down menu, choose Attributes. You can also select the desired element and choose Attributes in the drop-down menu at the end of the path bar. The list of attributes for the selected element is then displayed.
Click the New Attribute (+) icon at the top right of the main area to create an attribute for the selected element. You can specify the name, categories, data type, default value, and description of the attribute, as well as custom properties. For numeric data types, you can also set limits and time-series forecasting options. All attributes can be set as constants, hidden, or excluded as needed.
Properties can be configured with a default unit of measure and a display unit of measure. The default unit of measure is the unit of the collected quantity itself, and the display unit of measure is the unit used for presentation on the page. If the default unit of measure and the display unit of measure are inconsistent, automatic conversion will be performed when displaying the property value. For example, if the default unit is meter and the display unit is kilometer, and the property value is 1000, it will be displayed as 1 km. Both the default unit of measure and the display unit of measure must belong to the same unit of measure category (UOM Class).
Attributes support a wide range of data types. In addition to basic types (Int, Double, Varchar, etc.), they also support enumeration types and object types. Object types include file, video, attribute, and element. A file-type attribute can hold an uploaded file or a URL; video-type attributes are similar. An attribute of type 'attribute' references another attribute, while an attribute of type 'element' references another element.
Most importantly, attributes can be configured with a data reference. The reference can point to a TDengine metric or TDengine tag, indicating that the attribute is mapped to a specific column or tag value in a table within TDengine TSDB-Enterprise. The value of the attribute is then retrieved from the data source at access time.
The data reference for attributes also supports calculation formulas and string builders, making data references more flexible to support data standardization. A calculation formula means the attribute is calculated based on the values of other attributes. For example, the power attribute of a smart meter is obtained by multiplying the current attribute by the voltage attribute. We only need to configure the calculation expression. A string builder specifies a rule for generating a string, constructing a new string based on several input strings.
In the future, the data reference for attributes will not only be able to reference data from TDengine TSDB-Enterprise but also from other time-series databases or relational databases. After you create an attribute, you can modify, delete, copy, and paste it.
Configuring Data References
This section details how to configure data references for attributes. All data references are set via a string. Click the input box under the data reference type on the attribute editing page to open the data reference editing popup.
TDengine Metrics and TDengine Tags
A TDengine metric references a specific column of a table in TDengine TSDB-Enterprise; a TDengine tag references the tag value of a table in TDengine TSDB-Enterprise. They are set in the following format:
Connection Name/Database Name/Table Name/Column Name (or Tag Name)
For example:
TDengine/idmp_sample_utility/em-17/location
Here, TDengine is the connection name, idmp_sample_utility is the database name, em-17 is the table name, and location is the tag name.
Formula
A formula reference is set using an expression. It is ultimately converted into a TDengine SQL expression and executed by TDengine TSDB. A formula reference expression is a combination of attributes, operators, replacement parameters, constants, and functions. The attributes it references must be of a numerical type, and its output must also be numerical. For example:
log(current) * voltage +10 + TIME
The image below shows a configuration example for a formula reference expression:
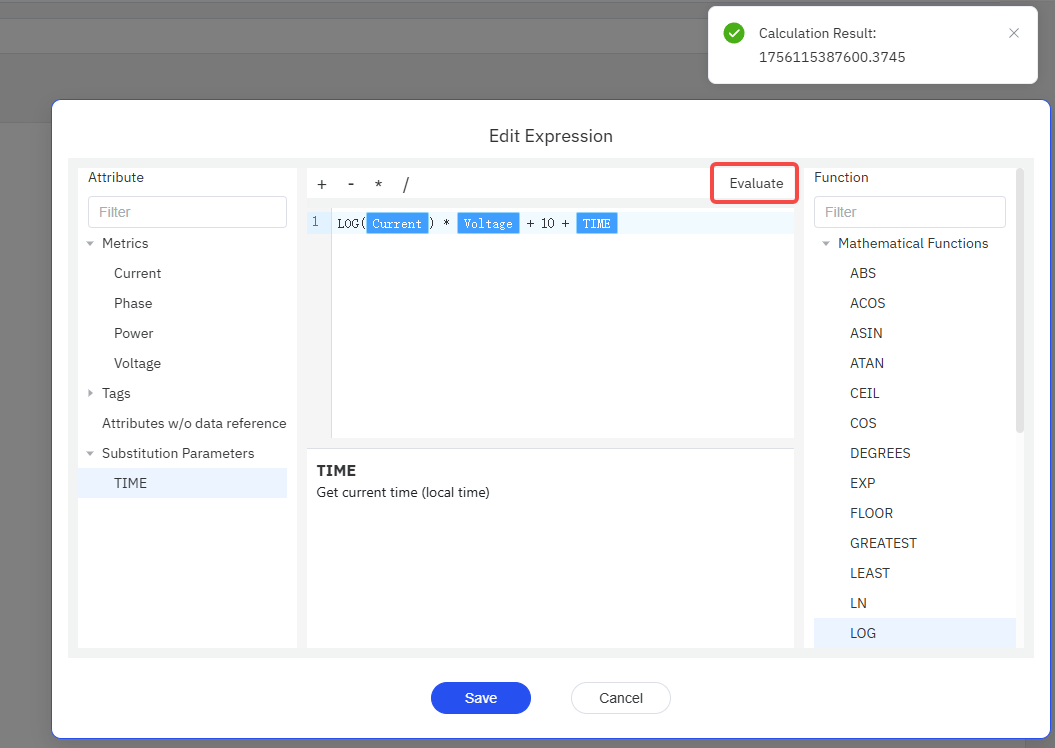
- Currently, the only available replacement parameter for formula reference expressions is
TIME, which will be replaced by the number of milliseconds corresponding to the current local time. - Currently, the attributes referenced by a formula expression can only be those of the current element. To reference an attribute
Afrom a non-local element, the recommended strategy is to add a new attributeA'to the current element, makingA'reference the same external data asA.
On the expression editing interface, you can click "Evaluate" at any time to test the current expression. IDMP will perform a validity check on the expression. If the check passes, it will further attempt to compute it. If a computation exception occurs, the corresponding SQL statement and SQL exception will be thrown. You can adjust the expression based on the exception information.
String Builder
The setting for a string builder reference is similar to that of a formula reference—it is also an expression, but its output is a string. Its input can be any attribute of the current element, not just numerical-type attributes. Commonly used string manipulation functions include:
CONCATfor concatenating strings.SUBSTRfor extracting substrings.CASTfor converting non-string type columns to string type.
String builders also have a richer set of available replacement parameters. In addition to time-related parameters, there are name-related parameters, such as: the current element name, the current attribute name, and the template name used by the current element.
You cannot use the plus sign (+) to concatenate strings. To concatenate strings, please use the CONCAT function on the right side of the formula editor interface. Each parameter of the CONCAT function must also be of string type. To concatenate a numerical-type attribute into a string, please convert it first using the CAST function, for example: CONCAT(Address, '-', CAST(Voltage as varchar)).
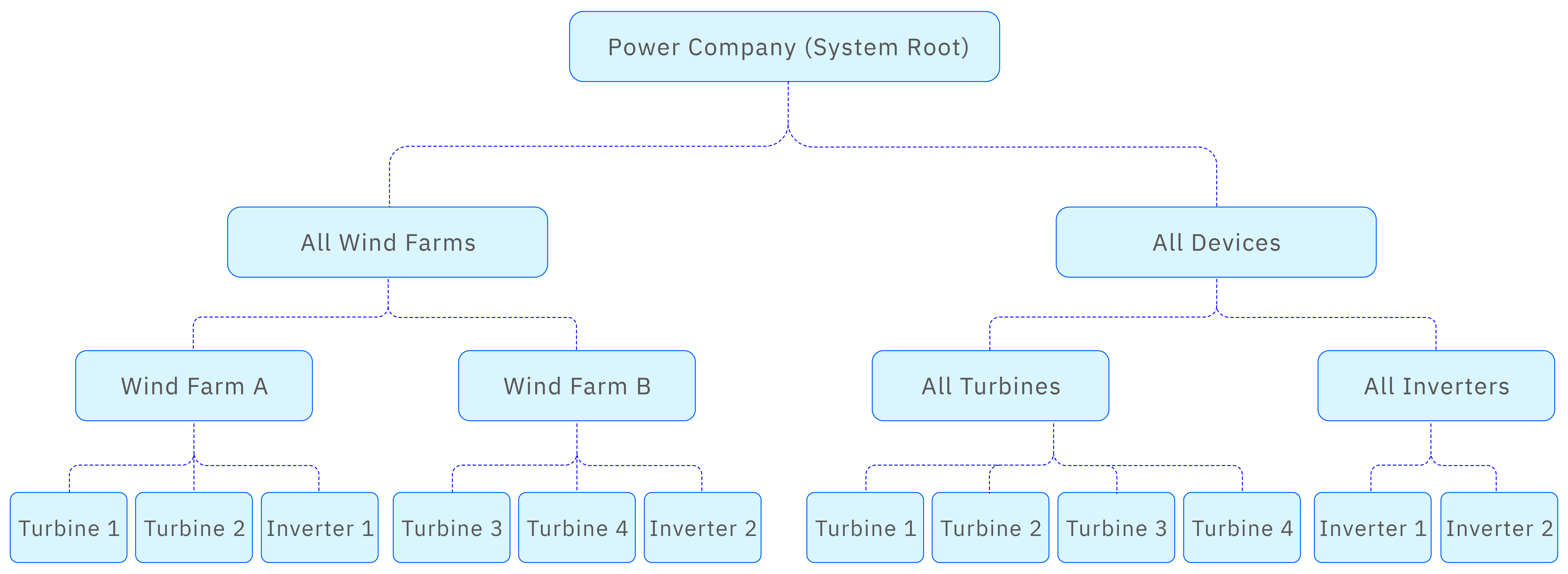
The image below shows a configuration example for a string builder reference:
CONCAT('Current voltage of ',LOWER(${Template#name}),' ',${attributes['Device ID']},' is ', cast(${attributes['Voltage']} as varchar), 'V')